
6.四月
我会在一切结束后重新处理。
1.select/poll/epoll
socket
定位为是linux上的一个api。当然其实各个操作系统上都有实现这样一个“socket”,但是我们一说到操作系统默认就是linux。理解这一点非常重要。
socket翻译过来叫插座,调用它可以创建一个网络连接。所以不如叫他《网络编程》。linux中一切皆文件,所以socket自然就是文件。linux有个概念叫fd(windows里叫句柄,是一个指针),也就是文件描述符,这就是文件的唯一id(直接叫他索引)。准确来说socket是通过linux内核暴露的api来操作linux内核。如果感到抽象,不妨想想前端调用后端的api接口,所谓“内核”有时候听起来很高级,其实只不过就是个相对于调用方的“后端”罢了,所以我归纳为内核就是一个提供了调用接口的功能实现者实体。
最常见来说,网络请求的协议是HTTP。那么HTTP只不过是对TCP的封装,本质上的特性都应该在传输层的TCP来看。为什么提到网络就这么喜欢说TCP?你就当他是个坤哥,后面可能有很多协议,但是本质上只是在模仿他,根本无法撼动“网络协议之父”这种经典的存在。所以在日常也要默认网络通信协议就是TCP。
复习一下,我们认为OS默认是linux,网络协议默认是TCP。再补充一点,从数据库层面看,索引默认是id。
确定一个通信实体(或说是进程?对我来说,实体、对象就是“东西”这个词的文雅说法罢了),需要IP和端口号,也就是我们常见的http://后面带的一串东西。比如http://127.0.0.1:7890就是我们常见的某串东西(doge)。再进一步说。网卡和IP地址是一对一的关系。而端口号是一个IP复用的序列号(对于这种类似于id的唯一标识,我想称他序列号),因为他就默认是1~65535。对的,我们完全可以用常见的编程语言go来说,这个socket其实就类似于NewSocket()这样一个函数,返回了一个网络连接实体,那么他叫socket。怎么去确定另一方通信实体呢?就是一个函数叫做bind()。
更进一步,listen()可以进行监听,accept()可以获取监听中的连接(没错,监听是拿不到连接的,还得主动去接收一下,就类似你收音机信号有了,但是你还得主动去搜查哪些频道是有节目的)。
上面说的是server是接收方,但是client怎么去发起连接?调用connect()即可。当然也需要提供服务端的IP和端口号来确定一个通信的目标实体。
这非常像网关的服务注册。对于client来说,我要注册我自己,我得提供我的IP和端口给对方,然后我也要确定对方的IP和端口才能告诉他我要注册。
后续就是TCP的三次握手了。简单来说我们server有两个队列,一个队列还没三次握手,一个已经三次握手。而后者中的连接实体才是可以通过accept()获取了。
还需要注意监听socket和传输数据的socket是两个实体。当连接建立,就可以用 read() 和 write() 函数来读写数据。
什么是I/O?
os中跨内核态与用户态的读写操作。可以直接简称为读写,是操作文件的input和output。
如何区分多个client连接?
现在我们有一个发送队列和接收队列。他是一直阻塞的,也就是说我发送了,另一方不去拿走(消费),他就残留在队列里。
TCP连接是可以被确定的,就像平面上确定了两个点就可以连出一条线段。我们通过画图展示可爱的四元组。
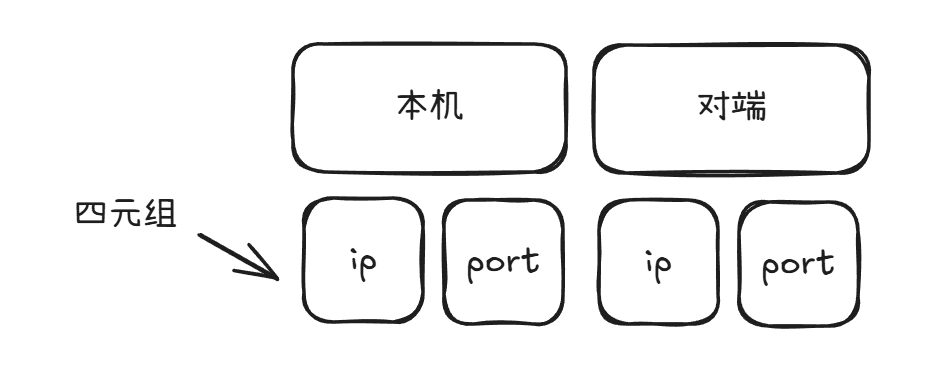
然后我们就会发现连接数量这个实体,在os里是一个文件。进一步说,连接是占用存储空间的。这就联想到我们的并发问题。也就是说,连接过多了,不就是OOM问题了吗?现在突然就想通了。因此,为了解决这种愚蠢的连接结构带来的愚蠢性能,我们需要采取一些智慧的措施。
首先想到我们可以多个进程,父进程负责监听(获取新链接),当accept()返回一个连接实体,就fork()出来子进程,只需要专注接收消息。那么连接断了,子进程退出即可,那些残留内容(僵尸进程)去做好垃圾回收。但是进程上下文切换资源开销比较大(为什么大?因为用户空间和内核空间的内存堆栈寄存器啥的都需要切换),所以我们想到可以改成多个线程。
一个进程中的线程们共享进程的资源,切换的时候只需要改现成的私有数据和寄存器等即可。
由于创建与销毁线程也需要开销,我们可以提前创建一堆线程。这一坨线程就叫《线程池》(是不是哥嘴里说出来就格外通俗易懂)。
那么按照我们之前说的,有一个已tcp连接的队列,我们的线程池就可以从队列里取出连接实体进行work了。
但线程终究也是实体,它是占用空间的一个员工,一次只让他干一个活太浪费了。有没有什么很贱的办法可以压榨员工,让他干更多活呢?接下来我们来说多路复用。
IO多路复用
让一个线程处理多个TCP连接。
和CPU并发同理,我们可以单个进程轮询多个socket以达到网络层面的并发。有没有注意到,两个形容词都是并发,他们本身就是同一个东西。
select/poll/epoll是三种多路复用模型。
他们也是内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll
select简单流程图如下
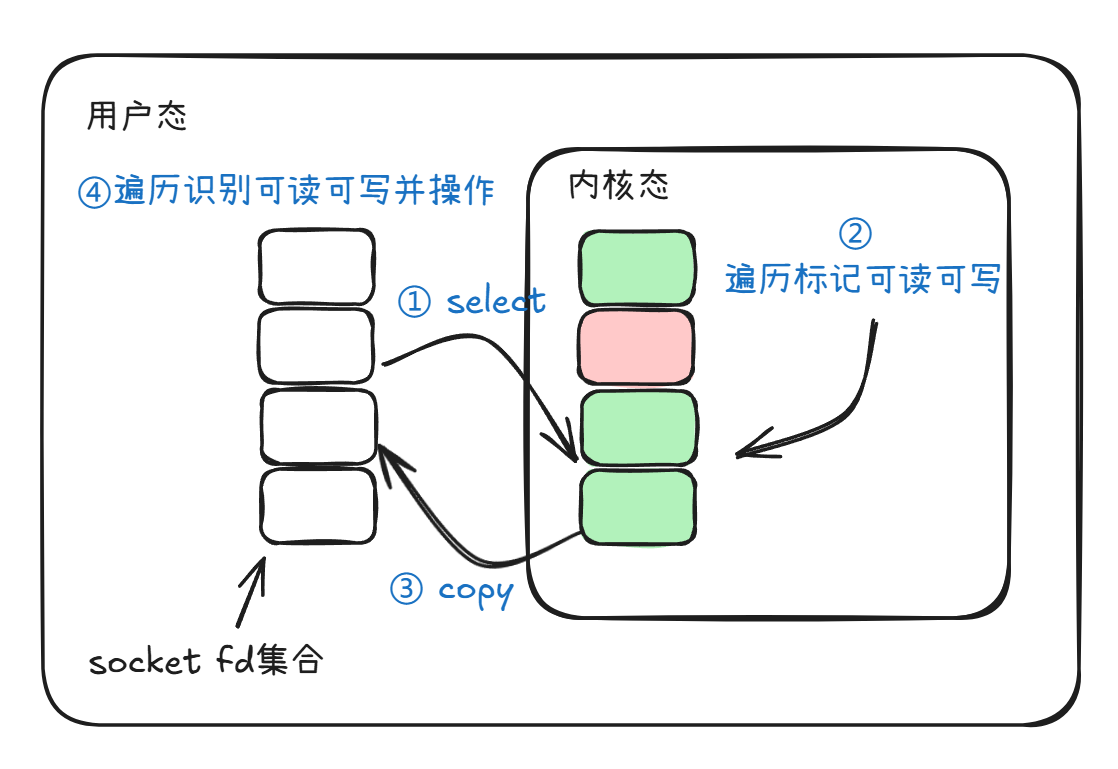
select 使用固定长度的 BitsMap 表示文件描述符集合,而且所支持的文件描述符的个数是有限制的。在Linux 系统中,由内核中的 FD_SETSIZE 限制,默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll差不多,但用了链表,它的大小就变得动态,稍微好一点点。
但是二者本质上都是线性遍历,O(n)复杂度,并发数一上来,性能损耗也非常大。
epoll
其实fd再进一步说,在高级语言里,就是类似于一个指针指向一个对象。
这一次,我们用epoll_create 创建一个 epoll对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到epfd中,最后调用 epoll wait 等待数据。
等待的伪代码如下
while(1){ |
类似于一直阻塞然后收到socket就处理。
epoll在这个领域就是所谓的《经典》。它有两个核心的数据结构
1.红黑树。对比线性遍历,它的增删改时间复杂度在O(logn)。而且它是长期维护,而不是每次都拷贝整个新的进来。
2.就绪队列。事件回调机制,复杂度在O(1),直接添加到就绪链表(双向链表)而不用拷贝和遍历。本质是一个队列,因此先进先出。
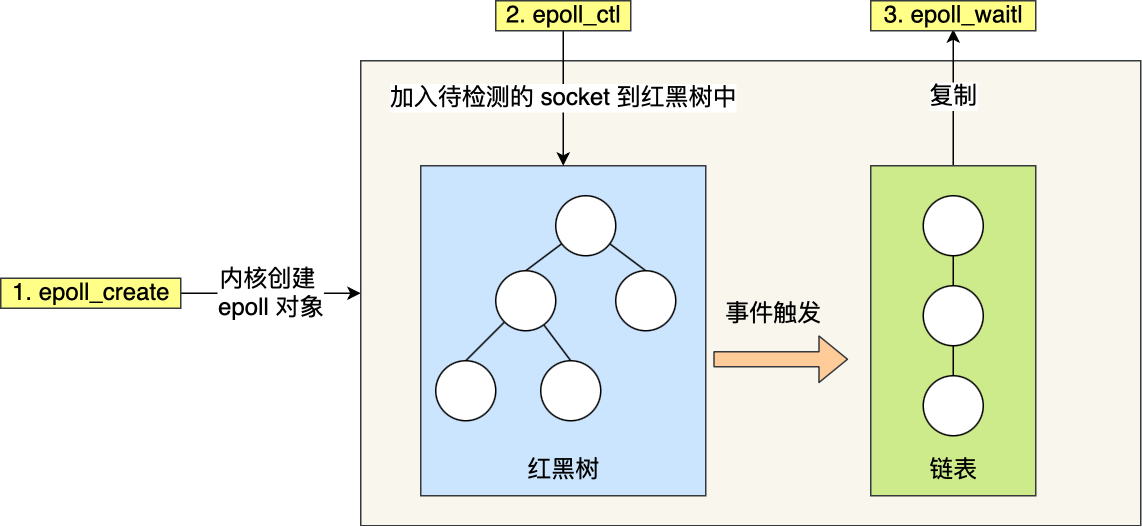
暂时放一张不是很明确的图,之后再优化一下。
补充一下,最大连接数就是最大FD数。
边缘触发和水平触发
理解来说,边缘触发就是循环疯狂读写+非阻塞IO(因为只通知一次或者只消费一次,因此要尽力一次操作完),但是《once通知》;而水平触发就是《multi通知》(反复触发直到被取消)
select/poll只支持水平触发,而epoll支持边缘触发和水平触发,水平触发是默认。边缘触发效率更高,因为避免了重复通知,并且只在状态变化时触发,减少了上下文切换。
2.slice
slice(切片)。
之前我们说到数组。但是在go里面统一使用了一个动态扩缩容的数组——slice。接下来研究一下这个。
关键代码在runtime/slice.go。至于为什么在runtime,因为你直接翻译他就是运行时,是语言自带的,而不是语言的包。
type slice struct { |
slice我们注意到他是一个结构体,因此对他的引用就是一个指针指向头,这和C的数组应该是一样的。
此外,我们的slice包括了len和cap,也就是容量和长度。有人会奇怪这俩不是一样的吗。因为我们slice是动态的,因此我们需要提前去分配内存空间。因此,cap(容量)就是分配的空间,而len是我们数组实际的长度因此一定是有一些位置是空着的。但是为什么空着?因为数组是连续的数据结构,我们需要提前分配连续的空间。如果数组需要加长,而后面的内存有东西,我们则需要再分配一块连续的内存,然后再拷贝过去。这里可以用画图的形式快速展示。
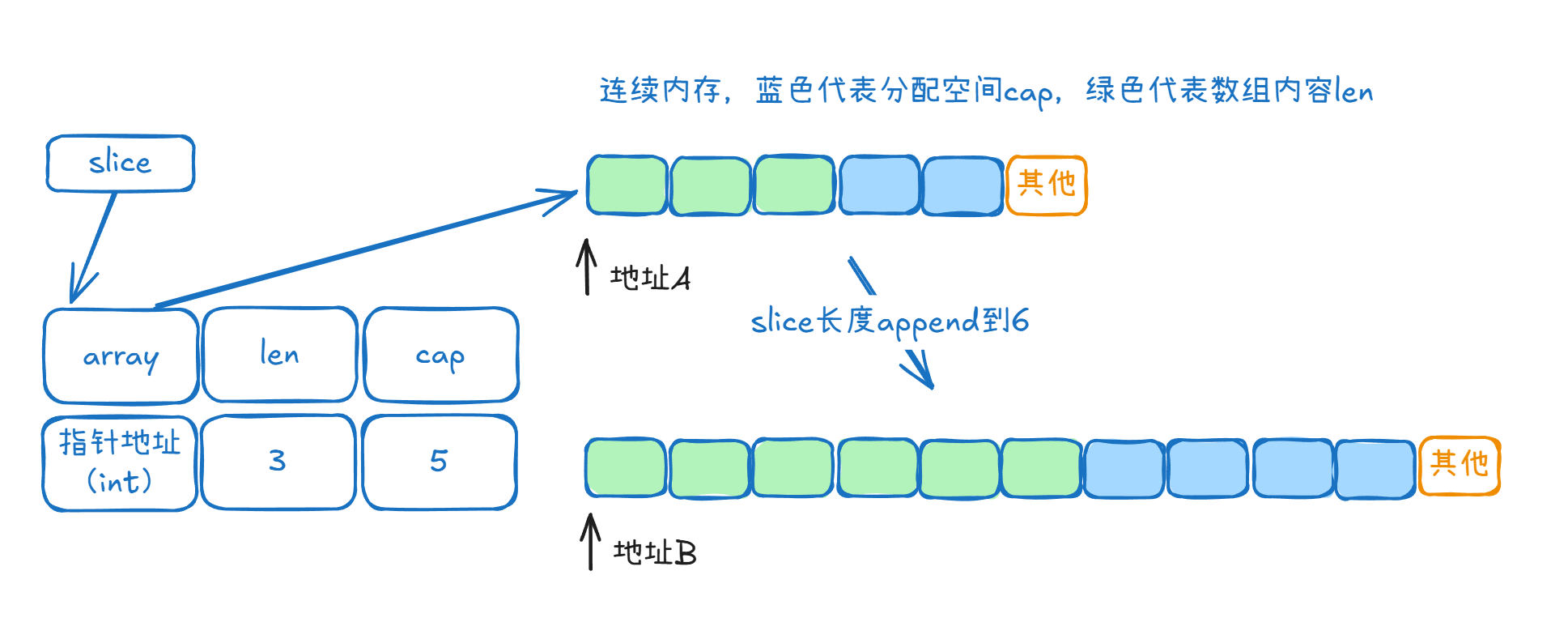
可以看到我们len到达6时,原来分配的内存只有5,不够了,因此需要拷贝到新的空间。扩容机制要求cap翻倍。
值传递
看一段代码
func process(data []int) { |
这时输出的data是没有那个append的1的,因为它只传递了值,没有传递地址。完全可以把他看成传进去了一个结构体,而这个结构体是值传递。解决它只需要在前面加上指针:
func process(data *[]int) { |
扩容机制
cap<len,则扩容,保持len<=cap
1.len<1024,cap翻倍
2.len>=1024,cap为原来125%
对于开发者来说容量的作用是什么?就是我们去new它的时候可以提前设置cap大小,来避免反复扩容带来的开销。
共享内存机制
切片一个特性是可以截取长度,就像python。
a := []int{1, 2, 3} |
这一段代码其实a和b操作的都是同一片内存,所以最后输出就是[1,2,4]
如何避免内存泄漏
内存泄漏就是有东西占用内存未被回收,缺不再被管理,显得被管理的内存越来越少,就是内存向外漏了,所以叫内存泄漏。
1.对于大slice,将不使用部分设置为nil,便于gc回收。
2.截取切片时,显式拷贝(copy()函数)小slice而不是直接截取。
基础操作
随便展示一下,具体怎么写需要自己查一下。
高效拷贝:copy()
添加内容:append()
创建:make()
3.consul部署
分两种情况,先说本地。直接docker-compose执行
services: |
如果是云环境,以sealos为例,拉取的时候可以加一个镜像地址,hub.fast360.xyz/hashicorp/consul
运行参数为
参考文献:
1.consul docker部署 https://juejin.cn/post/7244497027757277244
2.docker 国内镜像代理汇总https://www.coderjia.cn/archives/dba3f94c-a021-468a-8ac6-e840f85867ea
consul agent -server -ui -node=n1 -bootstrap-expect=1 -client=0.0.0.0 -advertise=<你的公网IP> -data-dir=/consul/data |
4.微信代理验签
说下思路就好,在固定公网的单机上开个nginx,做好转发,然后把target换成它就行。
5.微信支付native接入
一个文件就可以搞定,使用gopay这个包。这里展示各种行为怎么写。为了简化代码,我直接省掉错误处理
先列出各种参数,他们获取的地方各不相同,找就要好久
// 初始化配置 |
一个好习惯,包一层
type Controller struct { |
初始化
func (w *Controller) Init() { |
下单
// PlaceOrder Native支付下单(正确API) |
回调(关键)
// 支付通知回调 |
至于其它接口呢?说实话对于黑心商家来说只需要能收钱就好了,查询支付状态的话自己写的业务逻辑就可以搞定(doge)。
6.慢sql
慢sql指执行时间较长的sql语句,反映了一些性能,是个优化点。
一般我们云平台都是自带慢sql分析的。
这里就不讲怎么使用慢日志和分析工具了,主要考虑一些八股。
执行sql,最终都是一些cmd,如select,insert,update。这意味着我们期望是可以通过优化语句来改进查询。
危害:
1.阻塞所有DDL操作,占用大量内存(可能导致系统瘫痪),超时导致kill任务。
2.造成数据库幻读、不可重复读概率更大。
3.严重影响用户体验
语句优化:
2.用join代替select嵌套。嵌套其实是多次查询,可以叫O(n),而join是直接连接出来一张新表。关于join的使用可以参考这个博客学习https://leokongwq.github.io/2019/12/13/mysql-join-summary.html。
3.分页。尽量少返回,一次读太多会内存耗尽。
4.索引优化:索引列不要用运算;不要用不等于条件;不要用like和%模糊查;数据量太小不如全表扫描;索引要选对;
结构优化:
1.索引:
2.垂直分表:一部分列分出来一张表
3.水平分表:一部分行分出来一个表
参数调优:
EXPLAIN分析。
1.增加内存:内存够的时候不会阻塞
2.增加并发连接数:默认100。
3.调整InnoDB缓存。人尽皆知的bufferpool。innodb_buffer_pool_size:为InnoDB分配的内存大小,默认为8M,可适当增加该值提高性能。innodb_log_file_size:设置InnoDB redo日志文件大小,默认是5M。如果更新操作比较频繁,则应适当增加文本的大小,避免频繁写入磁盘造成性能瓶颈。
发生
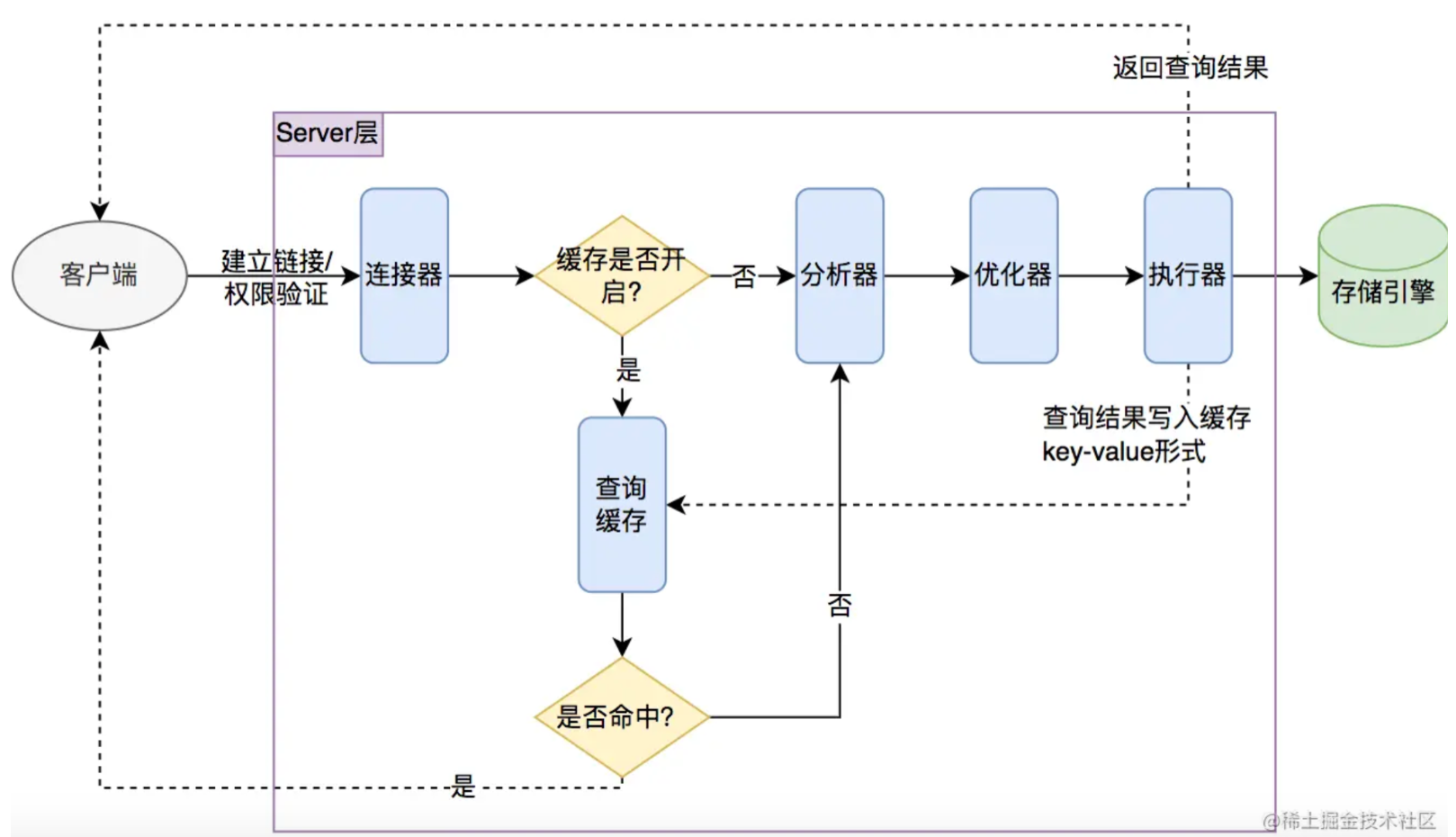
注意有一层缓存,这个缓存如果没命中,需要经过一堆计算然后再从树中取数据。出问题的关键在于数据量大,直接炸。
脑残题
一个表有字段a,b,c,创建了联合索引(a,b,c),以下哪些查询能用上索引?为什么?
1. WHERE a=1 AND b=2 AND c=3 |
- 解决方案:
- 能用上全部索引
- 只能用上a列索引(最左前缀原则)
- 不能使用索引(违反最左前缀原则)
- 能用上a和b列索引,c列不能使用(范围查询后列无法使用索引)
以下查询有什么问题?如何优化?
sqlSELECT * FROM orders |
解决方案:
问题:对列使用函数导致索引失效
优化:
SELECT * FROM orders
WHERE create_time >= '2023-01-01 00:00:00'
AND create_time < '2023-01-02 00:00:00';
如何优化包含大量OR条件的查询?
SELECT * FROM users |
解决方案:
使用IN代替:
SELECT * FROM users WHERE age IN (20,21,22,...,50);
对于连续范围更好用BETWEEN:
SELECT * FROM users WHERE age BETWEEN 20 AND 50;
7.线程、进程、协程
非常经典,但一直一知半解。直接懒得写了https://zhuanlan.zhihu.com/p/337978321。
8.web渲染经历了什么
DNS:Domain Name System 域名系统。
dns一般是53端口,udp传输。
域名一般是如www.bilibili.com
那么最后一个.就是根节点(一般省略)也就是根服务器。com属于顶级域名服务器。然后根服务器一般是中国电信这种管理。如果有CDN(内容分发网络),那么流程就是域名->cdn->IP。
浏览器去加载的时候,DNS先去把域名转换成IP。然后和IP建立tcp连接,然后web服务一般都是http连接建立。然后是服务器去响应三件套的代码(就是所谓的静态资源)。浏览器会做一个事情,解析html代码,并请求html中引用的资源。然后去构建dom树。这里开始涉及前端关键的一个东西了。dom其实就是document object model(文件对象模型)。简单来说就是理解为,界面上的组件(对象)。BOM其实就是浏览器,可以看成是dom的集合就可以。
然后我们会有样式,这里就用到cssom树构建。
然后又render树。翻译过来就是渲染树。这个渲染我的理解就是把html和css解析出来的内容进行搭配或融合,合成一个具有内容+样式的组件。或者简单地说就是html和css的融合。那么既然我们每个组件都已经渲染好了,但是我现在知道它在界面上展示在什么位置,所以需要一个布局layout是什么。知道了layout之后,我们就会进行一个paint,这个paint就是UI后端的一种逻辑感觉了,把一些抽象出来的各个节点给画出来。
最后还有一个composite合成,组合显示在网页上。
js引擎
浏览器核心组件之一,用于解析和执行js代码。
常见的js引擎:Google的V8(用于Chrome)、Mozilla的SpiderMonkey(用于Firefox)等
有一种编译器的味道,把js转换为机器语言,然后用就地解释或预编译的方式来加速js代码执行。
同时js engine管理内存、对象模型、时间处理等与js执行相关的功能。所以感觉就是js这种语言,它的语言拆成两部分,一部分是浏览器内核自带的,一部分是它的语法,这两者分开,和其他语言的区别也在这里。
渲染引擎
前面说到渲染阶段做的事情是html和css的融合。那么我们也会在浏览器内核看到相应的引擎。
Google的Blink(Chrome使用)、Mozilla的Gecko(Firefox使用)、WebKit(Safari使用)等。
这个事情可以根据不同设备进行页面的优化绘制,页面重新布局,js与页面交互使网页呈现效果最佳。(所以我们可以在浏览器禁用js脚本)
从头到尾做了什么
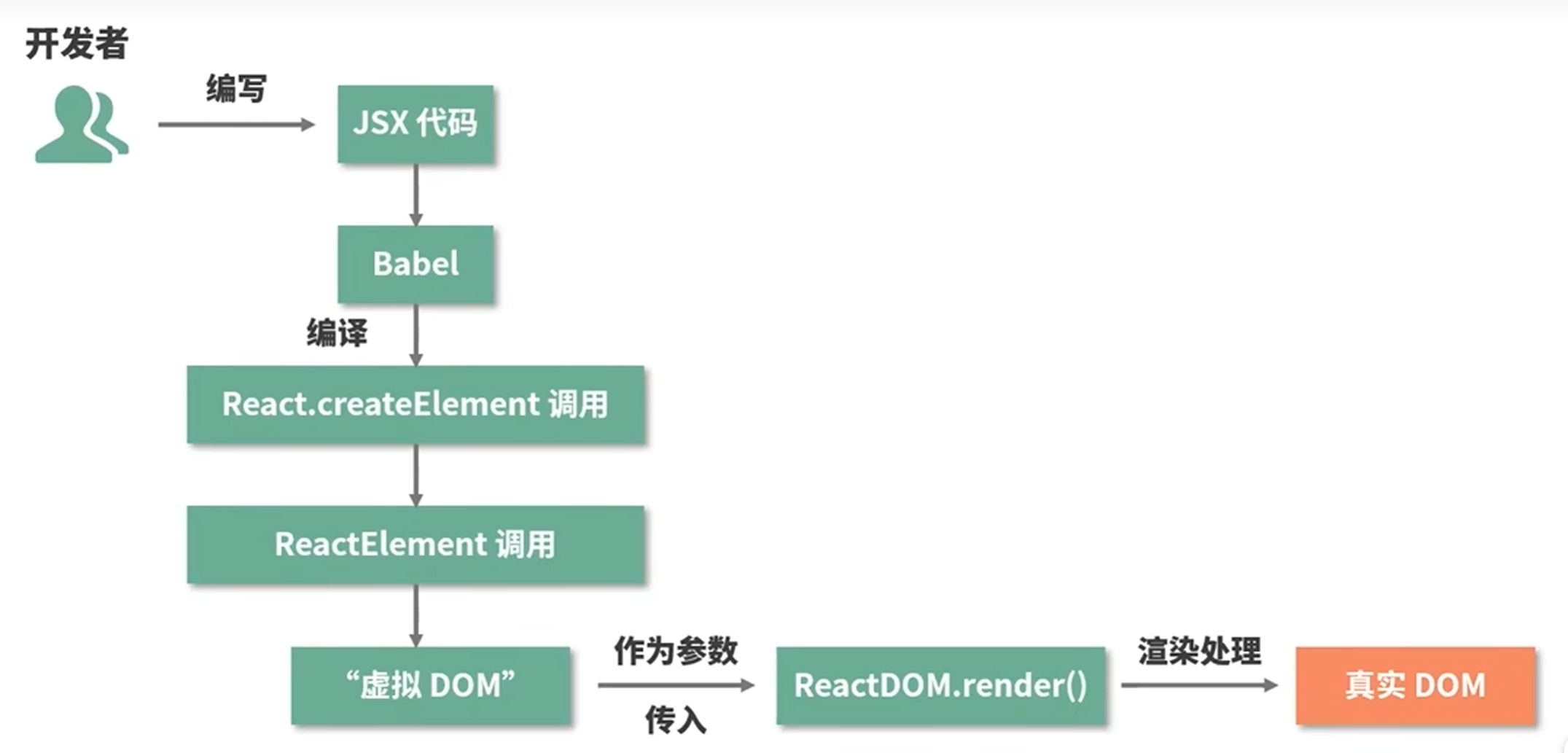
前端应该是有一个关键的名词:state。用于记录组件的状态。
那么在前端,首先调用setState,再react把他标记为需要重新渲染,解析jsx,实例化相应组件。调用render方法,生成新的vdom(虚拟dom)然后用diff算法比较前后两个虚拟dom树差异,找出需要更新的地方,然后把生成的新东西更新上去。最后浏览器渲染引擎进行页面布局和绘制。
js引擎和渲染引擎
所以这里我们会看见一个事情。js引擎和渲染引擎是一个前后配合的关系。相当于js引擎像一个生成静态的东西,而渲染引擎去把更新的部分去重新绘制,分工合作。然后我们也会发现这两个引擎都是存在于浏览器中的。
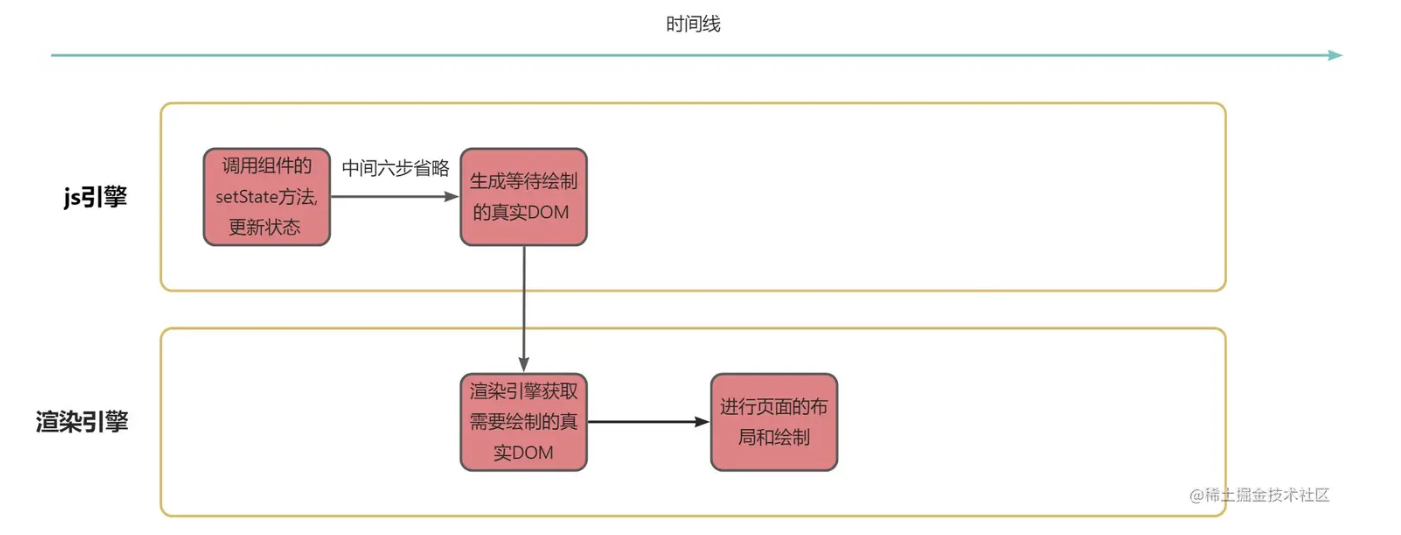
钩子函数
- useEffect:组件首次渲染或者每次依赖变更重新渲染后异步执行
- useLayoutEffect:在浏览器重新绘制屏幕前同步执行
useLayoutEffect的触发一定在useEffect之前。useLayoutEffect是同步执行,会阻塞浏览器重新绘制,所以在生成真实dom之后,React会开始触发需要执行的useLayoutEffect钩子。
JavaScript执行速度和页面绘制速度之间的差距可以是相当大的,所以即便两者是同时开始的,但是实际计算机内部执行速度来看,基本上绘制刚刚开始,useEffect函数都已经执行完了,所以在useEffect回调函数中获取元素,几乎不可能获取到最新的元素。(渲染嘎嘎慢)
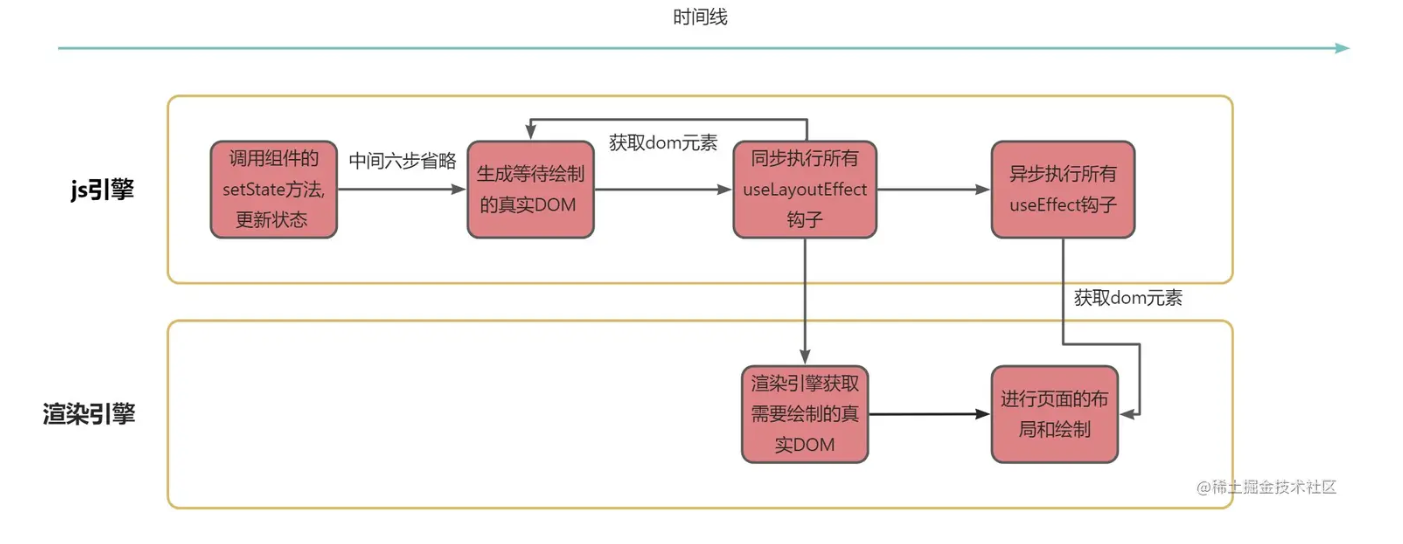
所以别useEffect和useLayoutEffect去更新非依赖的state值,前者会造成死循环(正常执行),后者会直接不再执行绘制。
方法是延迟获取的话,useEffect会因为图中上下都执行而导致闪现。useLayoutEffect会因为不执行绘制而避免了闪现。这就是这个钩子名称的由来,它为layout而生。
React在浏览器运行原理总结
在了解React Native的原理之前我们先简单回顾一下React和浏览器的工作原理: 首先Babel将React JSX语法糖编译成React.createElement表达式即虚拟DOM节点,然后利用虚拟DOM的Diff算法,对比出需要渲染的元素交由浏览器的渲染引擎渲染,从而形成丰富的浏览器页面。
rn渲染原理
整体架构
jsx->js
js core执行js,变成oc。具体是给一个数组描述oc对象的属性和方法
runtime 是一个通用抽象的术语,指的是计算机程序运行的时候所需要的一切代码库,框架,平台等。程序在运行时的状态和行为。
其中的思想主要就是一种键值对映射关系。
React Native 的启动流程涉及多个阶段,从加载 JavaScript 代码到与原生组件交互,每一步都涉及不同的机制。以下是 React Native 启动过程的一个简要说明:
启动流程
React Native 的启动流程大致上是通过以下几个关键步骤实现的:
- 启动原生应用并初始化 React Native 桥接(
RCTBridge)。 - 加载 JavaScript bundle(从本地或远程服务器获取)。
- 在 JavaScript 线程中执行应用逻辑,构建 React 组件树。
- 通过桥接将 JavaScript 生成的 UI 传递给原生组件。
- 通过桥接和事件机制实现 JavaScript 与原生代码的实时通信和 UI 更新。
这一流程的核心是通过桥接机制将 JavaScript 与原生层有效连接,实现跨平台的应用开发。
基于Bridge的架构原理
在0.59版本之前React Native使用的基于Bridge的架构方式
其实只需要知道,js和原生之间有一个bridge。那么这个里面是一个需要探索的东西。
jsc就是一种js引擎,和react有相似之处,都是去处理js代码。
而到了mobile app这边,或者说native这边,渲染引擎就是另外一个东西了。
而native我理解为原生代码,因此bridge可以相当于一个语言翻译器,在ios就是js->oc的转化。
缺点在于非常依赖bridge的转化,那么不断累积这个翻译过程会有性能上的问题
基于JSI的新架构原理
首先解释下新架构下的几个新概念
- JSI(Javascript Interface):JSI的作用就是让Javascript可以持有C++对象的引用,并调用其方法,同时Native端(Android、IOS)均支持对于C++的支持。从而避免了使用Bridge对JSON的序列化与反序列化,实现了Javascript与Native端直接的通信。 JSI还屏蔽了不同浏览器引擎之间的差异,允许前端使用不同的浏览器引擎,因此Facebook针对Android 需要加载JavascriptCore的问题,研发了一个更适合Android的开源浏览器引擎Hermes。
- CodeGen:作为一个工具来自动化的实现Javascript和Native端的兼容性,它可以让开发者创建JS的静态类,以便Native端(Fabric和Turbo Modules)可以识别它们,并且避免每次都校验数据,将会带来更好的性能,并且减少传输数据出错的可能性。
- Fabric:相当于之前的UIManager的作用,不同之处在于旧架构下Native端的渲染需要完成一系列的”跨桥“操作,即React -> Native -> Shadow Tree -> Native UI,新的架构下UIManager可以通过C++直接创建Shadow Tree大大提高了用户界面体验的速度。
- TurboModules:旧架构下由于端与端之间的隔阂,运行时即便没有使用的模块也会被加载初始化,TurboModules允许Javascript代码仅在需要的时候才去加载对应的Native模块并保留对其直接的引用缩短了应用程序的启动时间。
总结一下,旧架构中Bridge为React Native JS与Native交互的性能瓶颈,那么新架构的核心改变就是避免了通过Bridge将数据从JavaScript序列化到Native。